Abstract
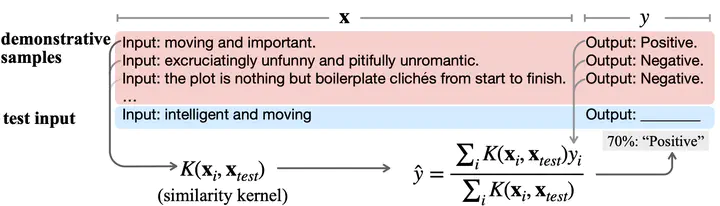
Large language models (LLMs) have initiated a paradigm shift in transfer learning. In contrast to the classic pretraining-then-finetuning procedure, in order to use LLMs for downstream prediction tasks, one only needs to provide a few demonstrations, known as in-context examples, without adding more or updating existing model parameters. This in-context learning (ICL) capabilities of LLMs is intriguing, and it is not yet fully understood how pretrained LLMs acquire such capabilities. In this paper, we investigate the reason why a transformer-based language model can accomplish in-context learning after pre-training on a general language corpus by proposing one hypothesis that LLMs can simulate kernel regression algorithms when faced with in-context examples. More concretely, we first prove that Bayesian inference on in-context prompts can be asymptotically understood as kernel regression as the number of in-context demonstrations grows. Then, we empirically investigate the in-context behaviors of language models. We find that during ICL, the attentions and hidden features in LLMs match the behaviors of a kernel regression. Finally, our theory provides insights on multiple phenomena observed in ICL field: why retrieving demonstrative samples similar to test sample can help, why ICL performance is sensitive to the output formats, and why ICL accuracy benefits from selecting in-distribution and representative samples. We will make our code available to the research community following publication.
Chi Han
Ph.D. Student at UIUC
My research interests are centered around theoretical and conceptual understanding of large language models (LLMs), meanwhile generate insights and develop useful tools for Natural Language Processing (NLP) practices.