Abstract
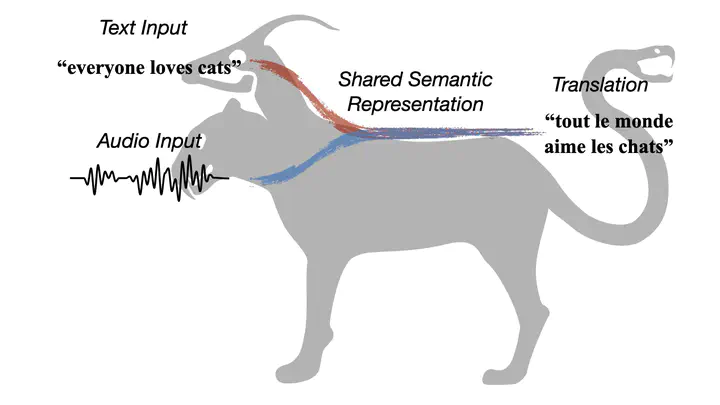
Having numerous potential applications and great impact, end-to-end speech translation (ST) has long been treated as an independent task, failing to fully draw strength from the rapid advances of its sibling - text machine translation (MT). With text and audio inputs represented differently, the modality gap has rendered MT data and its end-to-end models incompatible with their ST counterparts. In observation of this obstacle, we propose to bridge this representation gap with Chimera. By projecting audio and text features to a common semantic representation, Chimera unifies MT and ST tasks and boosts the performance on ST benchmarks, MuST-C and Augmented Librispeech, to a new state-of-the-art. Specifically, Chimera obtains 27.1 BLEU on MuST-C EN-DE, improving the SOTA by a +1.9 BLEU margin. Further experimental analyses demonstrate that the shared semantic space indeed conveys common knowledge between these two tasks and thus paves a new way for augmenting training resources across modalities.
Chi Han
Ph.D. Student at UIUC
My research interests are centered around theoretical and conceptual understanding of large language models (LLMs), meanwhile generate insights and develop useful tools for Natural Language Processing (NLP) practices.